The Learnable Typewriter
A Generative Approach to Text Analysis
ICDAR 2024 (Best Paper Award)

Abstract
We present a generative document-specific approach to character analysis and recognition in text lines. Our main idea is to build on unsupervised multi-object segmentation approaches and in particular methods which reconstruct images based on a limited amount of visual elements, called sprites. Our approach can learn a large number of different characters and leverage line-level annotations when available. Our contributions are twofold. First, we provide the first adaptation and evaluation of a deep unsupervised multi-object segmentation approach for text line analysis. Since these methods have mainly been evaluated on synthetic data in a completely unsupervised setting, demonstrating they can be adapted and quantitatively evaluated on real images, even as structured as text images, and using weak supervision are significant progresses. Second, we demonstrate the potential of the method we present for new applications, in particular in the field of paleography, which studies the history and variations of handwriting. We evaluate our approach on three very different datasets: a printed volume of the Google1000 dataset, the Copiale cipher and historical handwritten charters from the XIIth and early XIIIth century.
Approach
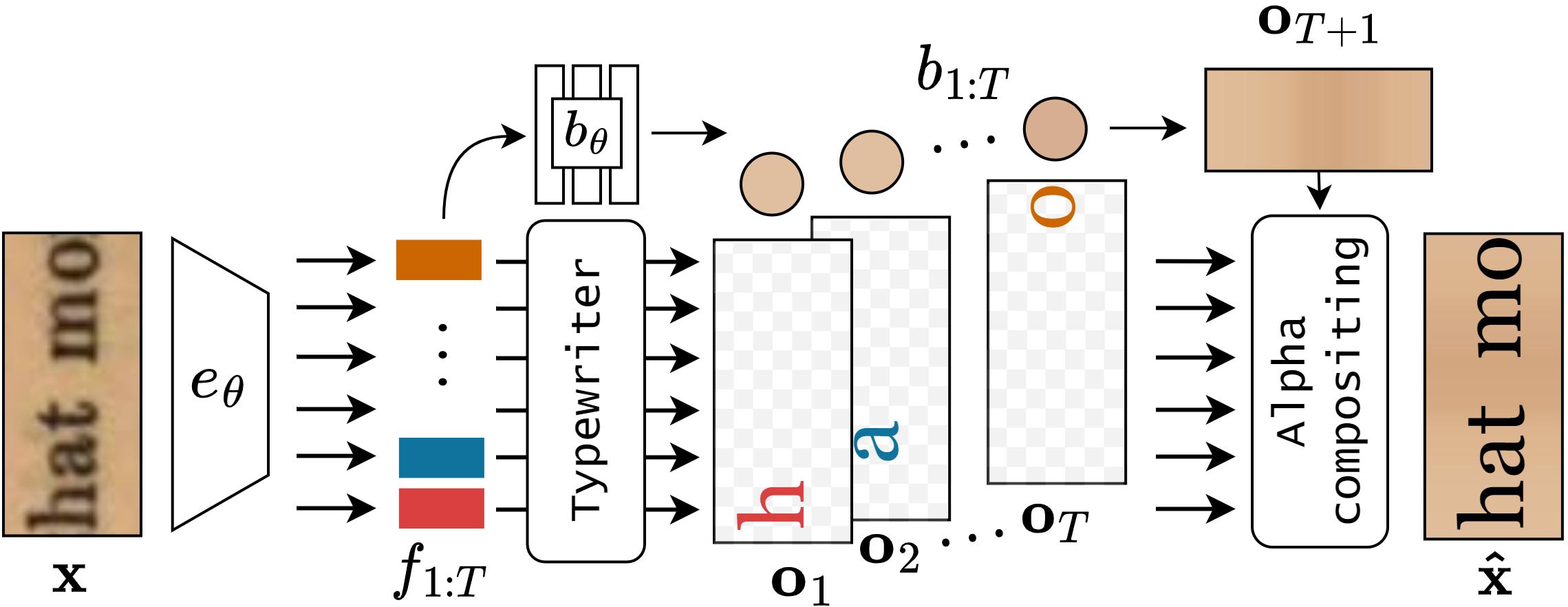
The Typewriter Module
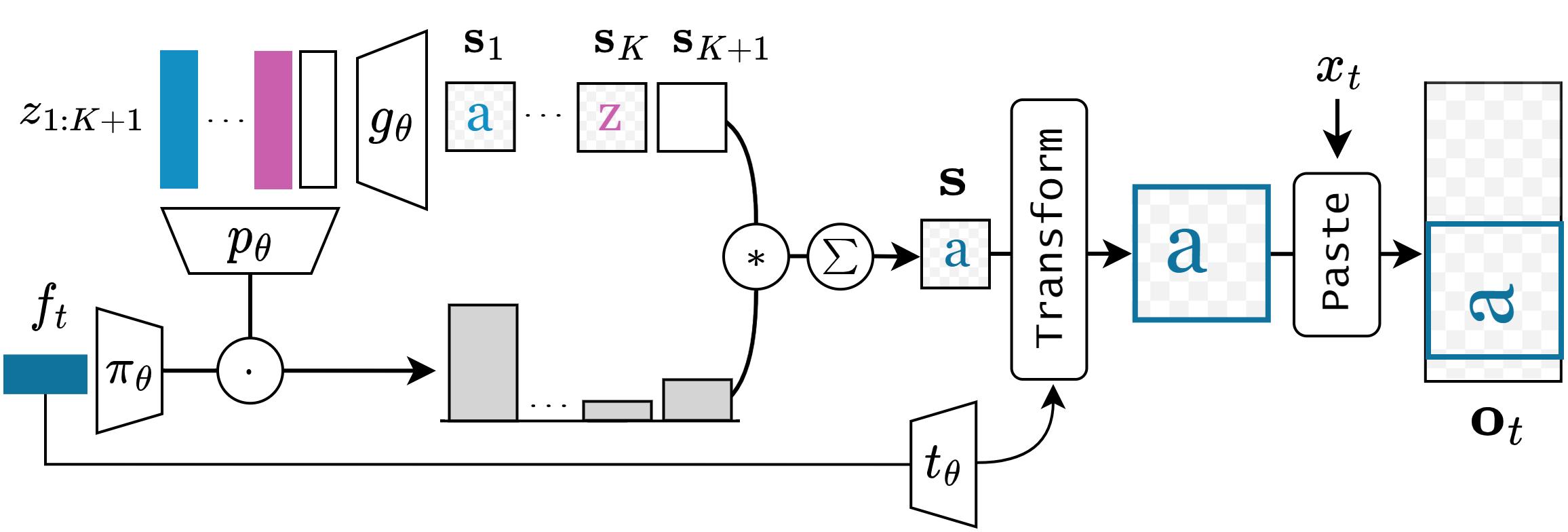
Learning to Extract Fonts & Scripts
In both the supervised and unsupervised settings our method produces meaningful sprites and accurate reconstructions, even despite the high number of characters and their variability.



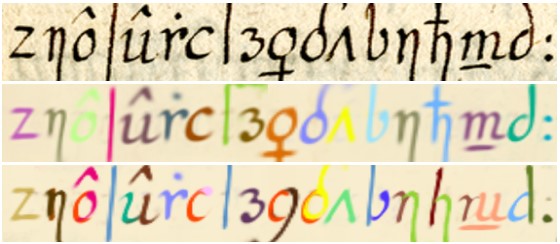
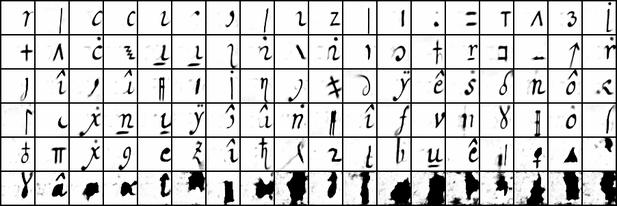
Historical Fonts
For 8 different fonts from the "ICDAR2024 Competition on Multi Font Group Recognition and OCR", we compare a-t, A-T between learned sprites (ours), and manualy extracted exemplars. Fonts are sorted by descending SSIM, computed on post-processed sprites (see details in supplementary material):








Note, that although fonts come from a single family, they may present allographs. For example, Italic contains different variants of “Q”, where a random exemplar can significantly differ from the one summarized using our method.
Paleography
Focusing on a collection of 14 historical charters from the Fontenay abbey we show that our approach can be used to perform paleographic analysis. After training on the whole collection of documents, we are able to display character variations across individual documents (hard to describe with words) by simply finetuning our approach to each one of them:




BibTeX
@article{the-learnable-typewriter,
title = {The Learnable Typewriter: A Generative Approach to Text Analysis},
author = {Siglidis, Ioannis and Gonthier, Nicolas and Gaubil, Julien and Monnier, Tom and Aubry, Mathieu},
publisher = {ICDAR},
year = {2024},
}
Acknowledgements
We would like to thank Malamatenia Vlachou and Dominique Stutzmann for sharing ideas, insights and data for applying our method in paleography; Vickie Ye and Dmitriy Smirnov for useful insights and discussions; Romain Loiseau, Mathis Petrovich, Elliot Vincent, Sonat Baltacı for manuscript feedback and constructive insights. This work was partly supported by the European Research Council (ERC project DISCOVER, number 101076028), ANR project EnHerit ANR-17-CE23-0008, ANR project VHS ANR-21-CE38-0008 and HPC resources from GENCI-IDRIS (2022-AD011012780R1, AD011012905).